(ICLR 2018) DCRNN
paper:https://arxiv.org/abs/1707.01926
code:https://github.com/liyaguang/DCRNN/
所解决的问题
- 复杂的路网空间依赖性
- 随着路况变化非线性变化的动态时间依赖性
- 长期预测本身就存在的内在的困难。
这项工作使用一个有向图来表示交通传感器之间的成对空间相关性,该图的节点是传感器,边权重表示通过道路网络距离测量的传感器对之间的接近度。我们将交通流动力学建模为一个扩散过程,并提出了扩散卷积运算来捕获空间依赖性。我们进一步提出了扩散卷积递归神经网络(DCRNN),它集成了扩散卷积、序列到序列结构和定时采样技术。
问题定义
交通预测的目标是根据之前从道路网络上的N个相关传感器观测到的交通流量,预测未来的交通速度。我们可以将传感器网络表示为加权有向图$\mathcal G=(\mathcal V,\mathcal E,W )$,其中$\mathcal V$是一组节点$\left|\mathcal V \right|=N$,$\mathcal E$是一组边,$W \in \mathbb R^{N \times N}$是表示节点接近度的加权邻接矩阵(例如,其道路网络距离的函数),将$\mathcal G$上观察到的交通流表示为图形信号$X \in \mathbb R^{N \times P}$,其中P是每个节点的特征数(例如速度、体积)。假设$X^{(t)}$表示在时间t观察到的图形信号,交通预测问题旨在学习一个函数$h(\cdot)$,该函数将之前的$T^{‘}$个历史图形信号映射到未来的$T$个图形信号,给定一个图G:
空间依赖性
通过将交通流关联到扩散过程来建模空间依赖性,该过程明确捕获了交通动力学的随机性质。该扩散过程的特征是$\mathcal G$上的随机游动,restart概率为$\alpha \in [0,1]$和状态转移矩阵$D_0^{-1}W$。这里$D_0=diag(W1)$是出度对角矩阵,其中$1\in \mathbb R^{N}$是全为1的向量,如同马尔可夫过程一样,这个随机游走在游走了足够长的步数后能得到一个稳定的分布$\mathcal{P}\in\mathbb{R}^{N\times N}$,在这个分布中的每一行$\mathcal{P}_{i,:}\in\mathbb{R}^{N}$,表示节点$i$与其余节点的相似性。
1 | 补充:这块内容其实在PPNP&APPNP那篇里介绍过,在jk-net那篇论文里有证明说GCN获得的表征最终会与随机游走获得的稳定分布一致,但传统随机游走由于没考虑restart,使得其在表征起始节点上并不好,所以该模型加入了一个restart的概率来改进。 |
这个稳定分布用数学公式表示为:
其中$k$是扩散步数。在实践中,我们使用扩散过程的有限$k$步截断,并为每个步骤指定一个可训练的权重。在实际模型中,还会利用入度矩阵再求一次,以更充分地捕获双向(upstream和downstream)的信息。(注意,是有向图,所以按入度和出度划分)
扩散卷积
$X \in \mathbb R^{N \times P}$ 和过滤器 $f_{\theta}$ 被定义为:
这里的$D_O^{-1}W$和$D_I^{-1}W^T$分别是由上面的出度、入度扩散操作所得的稳定分布,式中$\theta \in \mathbb R^{K \times 2}$是滤波器的参数,上式的计算如果$\mathcal G$是稀疏矩阵,可以使用递归稀疏稠密矩阵的计算方式大大减低计算复杂度。证明可以看论文详细介绍。
扩散卷积层
利用上式中定义的卷积运算,我们可以建立一个扩散卷积层,将$P$维特征映射到$Q$维输出。其中定义参数张量为$\Theta \in \mathbb R^{Q \times P \times K \times 2} = [\theta]_{q,p}$是用来进行维度转化的参数, $\Theta_{q,p,:,:} \in \mathbb R^{K \times 2}$是参数化第$p$维输入和第$q$维输出的卷积滤波器。因此,扩散卷积层为:
值得一提的是,文章里提到了扩散卷积层与频域GCN的关系。文中指出,ChebNet实际上是扩散卷积的一种特例。$X \in \mathbb R^{N \times P}$是输入,$H \in \mathbb R^{N \times Q}$是输出,扩散卷积层学习图结构数据的表示,我们可以使用基于随机梯度的方法对其进行训练。
时间依赖性
利用递归神经网络(RNN)来建模时间依赖性。特别是,我们使用门控循环单元(GRU),这是RNN的一种简单而强大的变体。我们将GRU中的矩阵乘法替换为扩散卷积,从而提出了扩散卷积门控循环单元(DCGRU)。
GRU补充知识:
GRU 原论文:https://arxiv.org/pdf/1406.1078v3.pdf
GRU不错的理解:https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be
GRU 背后的原理与 LSTM 非常相似,即用门控机制控制输入、记忆等信息而在当前时间步做出预测,表达式由以下给出:
GRU 有两个有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。
更新门
在时间步 t,我们首先需要使用以下公式计算更新门 $z_t$:
其中 $x_t$为第 $t$ 个时间步的输入向量,即输入序列 $X$的第 $t$个分量,它会经过一个线性变换(与权重矩阵 $W^{(z)}$相乘)。$h_{t-1} $保存的是前一个时间步 $t-1 $的信息,它同样也会经过一个线性变换。更新门将这两部分信息相加并投入到 $\sigma$ 激活函数中,因此将激活结果压缩到 0 到 1 之间。
更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少是需要继续传递的。这一点非常强大,因为模型能决定从过去复制所有的信息以减少梯度消失的风险。
重置门
重置门主要决定了到底有多少过去的信息需要遗忘,我们可以使用以下表达式计算:
该表达式与更新门的表达式是一样的,只不过线性变换的参数和用处不一样而已。
当前记忆内容
在重置门的使用中,新的记忆内容将使用重置门储存过去相关的信息,它的计算表达式为:
输入$x_t$与上一时间步信息 $h_{t-1} $先经过一个线性变换,即分别右乘矩阵 W 和 U。计算重置门 $r_t$ 与 $Uh_{t-1}$ 的 Hadamard 乘积,即$r_t$ 与 $Uh_{t-1}$ 的对应元素乘积。因为前面计算的重置门是一个由 0 到 1 组成的向量,它会衡量门控开启的大小。例如某个元素对应的门控值为 0,那么它就代表这个元素的信息完全被遗忘掉。该 Hadamard 乘积将确定所要保留与遗忘的以前信息。
当前时间步的最终记忆
在最后一步,网络需要计算$ h_t$,该向量将保留当前单元的信息并传递到下一个单元中。在这个过程中,我们需要使用更新门,它决定了当前记忆内容和$h_{t}^{‘}$前一时间步 $h_{t-1}$ 中需要收集的信息是什么。
现在我们有了当前记忆保留至最终记忆的信息$h_{t}^{‘}$,$z_t $与 $h_{t-1}$ 的 Hadamard 乘积表示前一时间步保留到最终记忆的信息
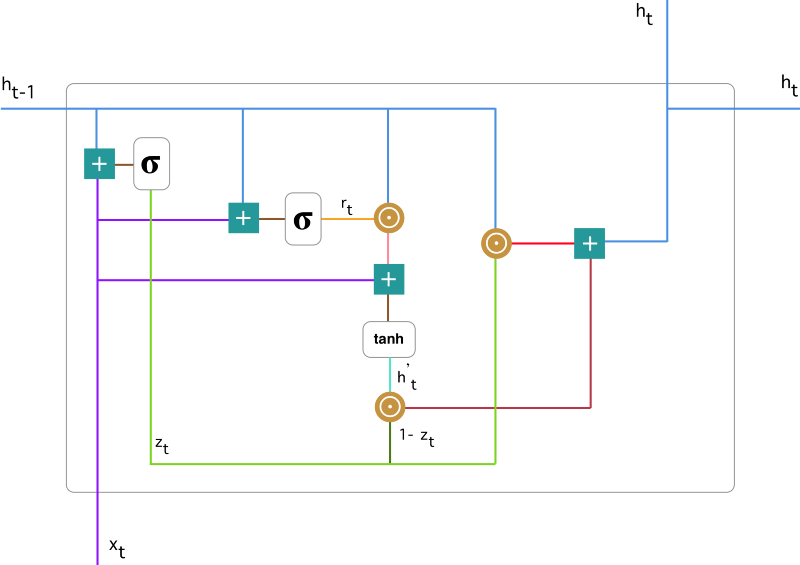
门控循环单元不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元,因此它利用全部信息而避免了梯度消失问题。
回到DCRNN当中,我们将GRU中的矩阵乘法替换为扩散卷积,从而提出了扩散卷积选通递归单元(DCGRU)。公式如下:
之后为了进行预测,模型在这一块设计成了$Seq2Seq$的形式。同时,为了提升$Seq2Seq$的效果,模型引入了$schedule sample$,为什么$schedule sample$能提升效果呢?原因如下:
$seq2seq$模型在训练和预测的时候实际上存在着差异,在训练过程中,是将已有的正确的序列输入进行预测,而在预测层中,则是根据上一轮生成的结果进行预测,如果上一轮结果错误,那么后续接连错误的概率就会很大。为了解决这个问题,$schedule sample$设定了一个概率$p$,使得在训练的过程中,有$p$的概率使用训练样本,有$1-p$的概率使用上一轮生成的结果进行预测。在DCRNN的训练策略中,还会随着训练的次数加深不断降低$p$,直到$p$为0,这样就使得模型能很好地适应预测阶段的模式。
参考:这个作者的理解,挺不错的 https://www.ooordinary.com/post/dcrnn
总结
第一篇时空图神经网络的文章,其实在序列这里一直是短板,没能理解是怎么序列实现的,自己又懒,一定要看一下RNN和$seq2seq$的代码实现
本篇文章主要理解的就是两个点:
- 随机游走得到稳定分布并利用扩散卷积
- 对时间依赖性GRU单元的理解和DCGRU的理解